
Can a text-to-image diffusion model be used as a training objective for adapting a GAN generator to another domain? In this paper, we show that the classifier-free guidance can be leveraged as a critic and enable generators to distill knowledge from large-scale text-to-image diffusion models. Generators can be efficiently shifted into new domains indicated by text prompts without access to groundtruth samples from target domains. We demonstrate the effectiveness and controllability of our method through extensive experiments. Although not trained to minimize CLIP loss, our model achieves equally high CLIP scores and significantly lower FID than prior work on short prompts, and outperforms the baseline qualitatively and quantitatively on long and complicated prompts. To our best knowledge, the proposed method is the first attempt at incorporating large-scale pre-trained diffusion models and distillation sampling for text-driven image generator domain adaptation and gives a quality previously beyond possible. Moreover, we extend our work to 3D-aware style-based generators.
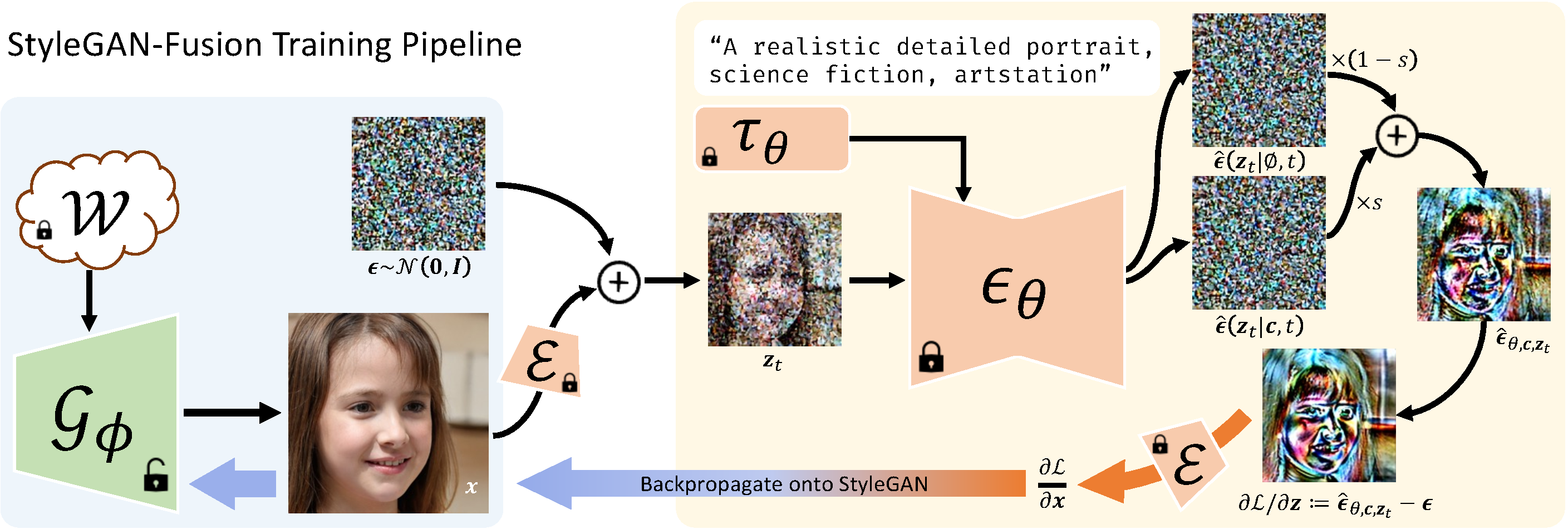
Overview of our StyleGAN-Fusion framework. The style-based generator receives the gradient backpropagated from diffusion UNet through encoder. All noises and noisy images are the decoded corresponding latents for visualization purposes.

Uncurated samples from our method on AFHQ-cat to dog, otter, hamster, fox, badger, liom, bear, and pig.

"3d human face, closeup cute and adorable, cute big circular reflective eyes, Pixar render, unreal engine cinematic smooth, intricate detail, cinematic"

"3d cat face, closeup cute and adorable, cute big circular reflective eyes, Pixar render, unreal engine cinematic smooth, intricate detail, cinematic"
We extend our method to 3D Geometry-aware generators from EG3D on the face and cat models provided by its authors.
Prompt: "3d human face, closeup cute and adorable, cute big circular reflective eyes, Pixar render, unreal engine cinematic smooth, intricate detail, cinematic"
Prompt: "3d cat face, closeup cute and adorable, cute big circular reflective eyes, Pixar render, unreal engine cinematic smooth, intricate detail, cinematic"
@article{song2022diffusion,
title={Diffusion Guided Domain Adaptation of Image Generators},
author={Song, Kunpeng and Han, Ligong and Liu, Bingchen and Metaxas, Dimitris and Elgammal, Ahmed},
journal={arXiv preprint https://arxiv.org/abs/2212.04473},
year={2022}
}

